muninのグラフを眺めてたら、CPU使用率が普段の5倍になってて、なんじゃこりゃー!という事になりました。
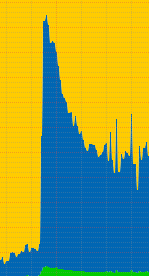
状況を調べた所、スクレイピングツールでレビュー全件をスクレイピングしている輩がおりまして、うちのサイトも有名になったもんだと思いつつも、さすがにCPU負荷がサイトに影響を与えていたので、アクセス拒否をする事にしました。##Apacheで拒否
Apacheでユーザーエージェント指定拒否する事が可能です。下記が実際のログでScrapyというツールを使ってアクセスしているのが分かります。
xxx.xxx.xxx.xxx - - [14/Mar/2014:00:00:06 +0900] “GET /review/420085/ HTTP/1.1” 200 8750 ”http://www.anikore.jp/anime_review/3753/page:33” “Scrapy/0.22.2 (+http://scrapy.org )”
Apacheの SetEnvIfディレクティブを使って、環境変数を設定し、対象を拒否します。これでhttpd.confを保存後、configtest&gracefulをすれば完了です。
SetEnvIf User-Agent “Scrapy” deny_ua <= これを追加
Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all Deny from env=deny_ua <= これを追加
Dev HTTP Clientで確認
Google Chrome AppのDev Http Clientを使用して、httpリクエストを送信してテストしましょう。
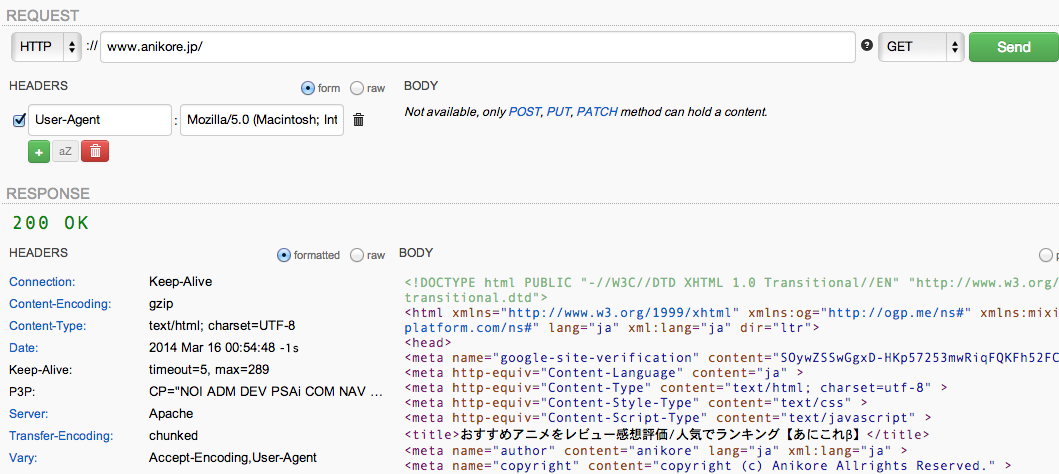
通常の場合
Chromeのユーザーエージェントの場合は正常にアクセスできますね。
Scrapyのリクエストの場合
先ほどのScrapyのアクセスログを元にユーザーエジェントを指定してアクセスしようとすると403 Forbiddenで拒否
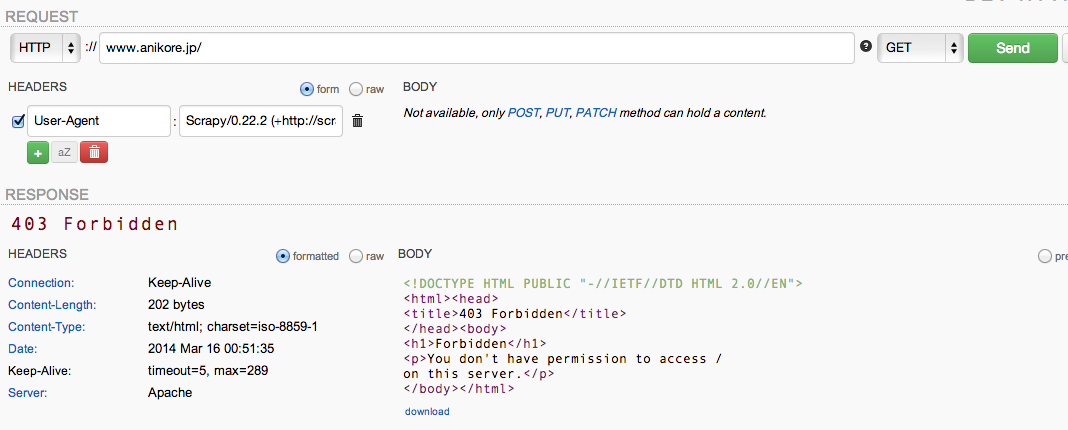
と、Scrapyから来た場合はちゃんと弾けているよというのが確認出来ましたので、これでデプロイしました。 まぁ正直言って、UserAgentが改ざんされてしまったらこれでは弾けないんですが、あくまで対策の一環という事で。